本文共 2073 字,大约阅读时间需要 6 分钟。
改进点(跟前几篇的SVD比):
一句话总结:当数据样本只有隐式反馈时,以前的数据建模方式便不再适用。原因:1.隐式反馈中默认只有正样本(one-class问题);2.未观测到的样本默认为负样本(显然不合理,也可能喜欢)。
概念:
显式反馈:形如rating矩阵,这种直接评分的矩阵,称之为显式反馈;
隐式反馈:构造样本时,数据不是评分、评论这种直接表示喜好,使用点击、下单这种数据,侧面表示喜好的形式,称之为隐式反馈。
我们前面讲的算法都是针对显式反馈的评分矩阵的,因此当数据集只有隐式反馈时,应用上述矩阵分解直接建模会存在问题。
主要有两方面的原因:
首先,隐式反馈数据集中只存在正样本,即 rij=1,∀𝑟𝑖𝑗∈R。此时,不能够只使用正样本进行优化,而忽略了未观测样本,否则会造成 trivial 但是无用的解,例如把所有的隐向量都预测成向量空间中的同一个点上。
其次,不能够把所有的未观测样本都当做是负样本,因为这些未观测的样本既可能是用户不喜欢,也有可能是用户未曾看到但是实际上是喜欢的。虽然可以把预测用户行为看成一个二分类问题,猜用户会不会做某件事,但实际上收集到的数据只有明确的一类:而用户明确 “不干” 某件事的数据却没有明确表达。这类问题在业内称为 One-Class,One-Class 数据也是隐式反馈的通常特点。
主要思想:
为解决上述问题,引入WRMF (weighted regularized matrix factorization)。该方法对每个训练样本都加一个权重,来表征用户对物品偏好的置信度。这个权重通常使用隐式反馈行为的次数或者一些量化指标的转换,比如浏览次数或观看时间等。权重可以减少未知样本的影响力,这些未知样本的权重一般的比观测样本的权重小的多.
目标函数:
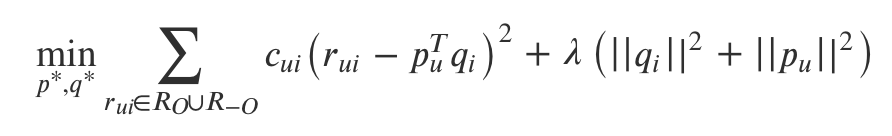
其中,𝑅𝑂 代表观测样本,都为正样本,即 𝑟𝑢𝑖=1, 𝑅−𝑂 代表未观测样本,都为负样本,即 𝑟𝑢𝑖=0。𝑐𝑢𝑖 是样本 𝑟𝑢𝑖 的权重,也就是置信度,在计算误差时考虑反馈次数,次数越多,就越可信。置信度一般也不是直接等于反馈次数,根据一些经验,置信度 𝑐𝑢𝑖 可这样计算:
![]()
其中阿尔法是一个超参数,需要调教,默认值取 40 可以得到差不多的效果,𝐶𝑢𝑖 就是次数了。
此外,还可以多了解几点:
- 该损失也可以通过下个算法 PMF 推导,此时 1/𝑐𝑢𝑖 即为 PMF 中评分
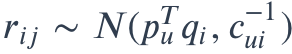 的方差。𝑐𝑢𝑖 越大,方差越小,置信值越高。
的方差。𝑐𝑢𝑖 越大,方差越小,置信值越高。 - 这种加权的方法除了可用于隐式反馈,还可以根据某些短期策略或因素的影响进行加权,比如一些短时间大规模的广告会影响一部分物品的隐式反馈,而这并不能恰当地反应长期的特点。
$One-Class 的负样本如何采样?
因此,One-Class 这种问题不能讲所有的缺失值作为负类别,矩阵分解的初心就是要填充这些值,如果都假设他们为 0 了,那就忘记初心了。应对这个问题的做法就是负样本采样,即挑一部分缺失值作为负类别样本即可。
常见的有两个方法:
- 随机均匀采样和正类别一样多;
- 按照物品的热门程度采样。
按照经验,第一种不是很靠谱,第二种在实践中经过了检验。
想一想也不难理解,在理想情况下,什么样的样本最适合做负样本?
就是展示给用户了,他也知道这个物品的存在了,但就是没有对其作出任何反馈。问题就是很多时候不知道到底是用户没有意识到物品的存在呢,还是知道物品的存在而不感兴趣呢?
因此按照物品热门程度采样的思想就是:一个越热门的物品,用户越可能知道它的存在。那这种情况下,用户还没对它有反馈就表明:这很可能就是真正的负样本。
按照热门程度采样来构建负样本,在实际中是一个很常用的技巧,其实 Word2Vec 学习过程,也用到了类似的负样本采样技巧.
其他:
工作中,我们的数据多为隐式反馈样本,只将用户-item之间的点击、下单行为加权组合,作为矩阵的元素。加入有300w item,500w用户,两两交叉会有300W * 500w的样本,构造的rating隐式矩阵中,非零部分最多3亿,占全部user-item对不足1%,并且我们工程上也不支持这么大的数据量进行分解处理,因此,过滤掉负样本,将user和item之前没有交互的过滤掉,只留下rij大于0的数据。
那么点击下单加权方式该怎么处理呐?举个例子,可以定义曝光、点击、下单的权重分别为1,3,5。经过计算后,统计了其占比:1占45%,3 35% 5 20%;
这种处理方式还是很粗糙,使用sparkml中的ALS算法求解,内置的算法,不能对损失函数加权处理,也没有对负样本(user-item交叉为0)进行负采样。线上使用时,计算了user和item之间的相似度,用于模型迭代,对订单有提升。
写完这边博客,带给我的较大的收获是,不能生搬硬套,结合实际问题借鉴有帮助的地方。落地算法前,要做充分的调研,调研时间不能太少,不能泛泛查询资料。否则你在后续执行时,都不知道对错,都不知道何以然。
参考:
1.
转载地址:http://pvxwn.baihongyu.com/